Beauty Of Algorithms 14 Summary. Sorting Enhancement
Feb 4, 2019#Algorithms
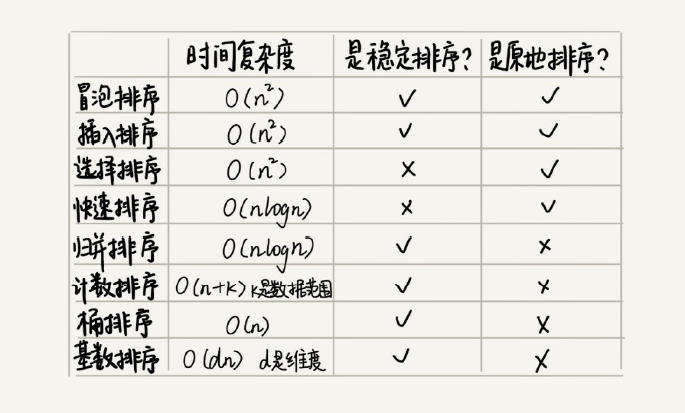
选择排序算法的原则
- 线性排序时间复杂度很低但使用场景特殊,如果要写一个通用排序函数,不能选择线性排序
- 为了兼顾任意规模数据的排序,一般会首选时间复杂度为O(nlogn)的排序算法来实现排序函数
- 同为O(nlogn)的快排和归并排序相比,归并排序不是原地排序算法,所以最优的选择是快排
优化快速排序
导致快排时间复杂度降为O(n^2)的原因是分区点选择不合理,最理想的分区点是:
被分区点分开的两个分区中,数据的数量差不多。
优化分区点有2种常用方法:
三数取中法
从区间的首、中、尾分别取一个数,然后比较大小,取中间值作为分区点
如果要排序的数组比较大,那三数取中可能就不够用了,可能要五数取中或者十数取中
随机法
每次从要排序的区间中,随机选择一个元素作为分区点
递归发生堆栈溢出的解决方法
限制递归深度,一旦递归超过了设置的阈值就停止递归
在堆上模拟实现一个函数调用栈,手动模拟递归压栈、出栈过程,这样就没有系统栈大小的限制
通用排序函数实现技巧
- 数据量不大时,可以采取用空间换时间的思路
- 数据量大时,优化快排分区点的选择
- 防止堆栈溢出,可以选择在堆上手动模拟调用栈解决
- 在排序区间中,当元素个数小于某个常数是,可以考虑使用O(n^2)级别的插入排序
- 用哨兵简化代码,每次排序都减少一次判断,尽可能把性能优化到极致